




![]()
In order for you to keep up with customer demand, you need to create a deployment pipeline. You need to get everything in version control. You need to automate the entire environment creation process. You need a deployment pipeline where you can create test and production environments, and then deploy code into them, entirely on demand.
—Erik to Grasshopper, The Phoenix Project [1]
Continuous Deployment
Continuous Deployment (CD) is the process that takes validated Features in a staging environment and deploys them into the production environment, where they are readied for release.CD is the third aspect in the four-part Continuous Delivery Pipeline of Continuous Exploration (CE), Continuous Integration (CI), Continuous Deployment, and Release on Demand (Figure 1).
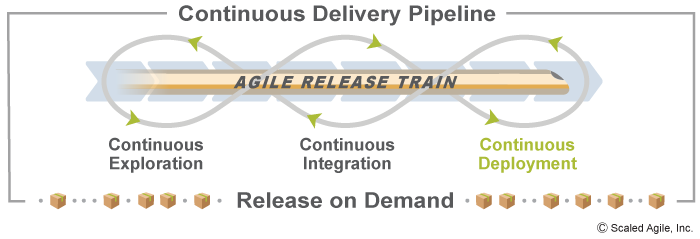
The ability to Release on Demand is a critical competency for each Agile Release Train (ART) and Solution Train. It allows businesses to respond to market opportunities with the highest-value solutions in the shortest sustainable lead times, and at a rate that permits customers to absorb the new functionality.
To support a business that wants to release on demand, features must be waiting and verified in production before the business needs them. Therefore, it’s optimal to separate the deployment process from the release process so that deployed changes move into the production environment in a manner that does not affect the behavior of the current system. This gives the teams the ability to make smaller, incremental changes, which can be deployed to production continually but are not released to end users until the time is right.
This article, Continuous Deployment, details the activities and practices a Lean Enterprise needs to continuously deploy potential end-user value to production.
Details
Traditional development practices treat deployment and release as the same activity: changes deployed to production are immediately available to users. This motivates behaviors that make applying certain design thinking practices, such as A/B Testing, hard to implement, and serve to inhibit the flow of value.
Continuous deployment separates the deployment and release process. This promotes design thinking practices and the flow of value by:
- Targeting functionality to specific customers – Separating deployment from release enables the organization to target customers with specific functionality, allowing the organization to assess the impact of the release before deploying functionality to all customers.
- Promoting experimentation, such as A/B Testing – Design thinking practices, such as A/B Testing, require the ability to present different functionality to targeted users, gathering the data that helps create designs optimized for user needs.
- Promoting small batches – Prior choices made in the pipeline, such as automated testing, make deploying in small batches easier.
- Releasing on business needs – Enterprises tend to release infrequently when deploying a release is complex and error-prone. Conversely, when deployment and release are separated, and investments are made to ensure both are automated and low-risk, enterprises can release on demand, substantially increasing business agility. For example, a release can be in production ahead of a marketing milestone, giving the organization complete flexibility in maximizing all aspects of the delivery of value.
To enable these business capabilities, ARTs focus on reducing the transaction cost and risk of production deployments by implementing continuous deployment. Working to ensure that the deployment process is a routine, predictable, “non-event,” teams help their organizations achieve continuous deployment.
The Four Activities of Continuous Deployment
SAFe describes four activities of Continuous Deployment, as illustrated in Figure 2.
- Deploy to production describes the practices necessary to deploy a solution to a production environment
- Verify the solution describes the practices needed to make sure the changes operate in production as intended before they are released to customers
- Monitor for problems describes the practices to monitor and report on any issues that may arise in production
- Respond and recover describes the practices to rapidly address any problems that happen during deployment
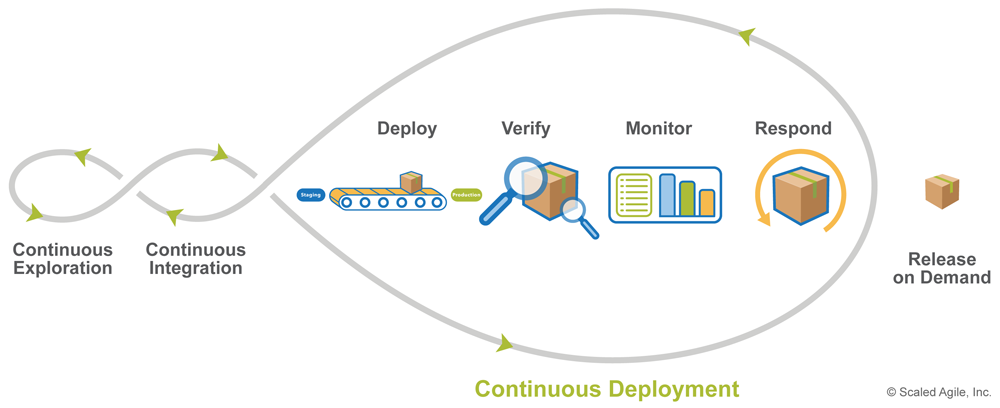
Deploy to Production
Deployment is the migration of changes into a production environment. In the Continuous Delivery Pipeline, such changes are deployed continuously. Thus, partial functionality—i.e., deploying some of the stories that comprise a feature—can be implemented into production.
Consider a user story map in which 27 stories capture the functionality of a Feature. In traditional deployment, all 27 stories would be implemented and deployed in a large batch. Using continuous deployment, individual stories can be deployed in ‘dark mode’—employing feature toggles, for example—so that they can be validated, monitored, and queued in a bona fide production setting. When the full set of features has been deployed, the business can release them to users.
Ideally, the deployment pipeline triggers the deployment process automatically following a successful build, integration, and validation. This makes the entire workflow, from code-commit to production-deploy, a fully-automated “one-click” process. Highly sophisticated enterprises can reliably deploy any time of day, any day of the week, and any week of the year—even during peak periods.
Seven practices contribute to the ability to deploy:
- Dark launches – the ability to deploy to a production environment without releasing the functionality to end users
- Feature toggles – a technique to facilitate dark launches by implementing toggles in the code, which enables switching between old and new functionality
- Deployment automation – the ability to deploy a tested solution automatically from check-in to production
- Selective deployment – the ability to deploy to specific production environments and not others based on criteria such as geography, user role, etc.
- Self-service deployment – when automation deployment is not fully implemented, self-service deployment allows a single command to take solutions from staging to production
- Version control – maintaining environments under version control enables fast deployment and fast recovery
- Blue/green deployment – a technique that permits on-demand switching between staging and production environments
Verify the Solution
Before being released to end users, deployments must be verified for functional integrity and robustness. When they’re coupled, deployment and release have to happen almost instantaneously, as decisions must be made immediately about whether to rollback or not. When they’re decoupled, however, there’s room to test new functionality extensively in production before approving it for release. Immediately following the migration to production, solutions undergo a final round of testing. Typically, this is conducted through smoke testing and/or light user acceptance testing, but also as a stress and performance test, which can only be done in production. This provides a critical sanity check that tests the behavior of the solution in an actual production environment.
Continuous Integration will have already provided assurance upstream that the solution will behave as expected in production; however, surprises do occur. When verification reveals critical defects, deployments must either be rolled back or fixed quickly to prevent them from contaminating the production environment or disrupting the flow of business.
Once the deployed changes are verified in the production environment, they are one step closer to being released. Four practices help drive verification:
- Production testing – the ability to test solutions in production when they are still ‘dark’
- Test automation – the ability to test repeatedly via automation
- Test data management – managing the test data in version control to create consistency in automatic testing
- Testing nonfunctional requirements (NFRs) – system attributes such as security, reliability, performance, maintainability, scalability, and usability must also be thoroughly tested before release
Monitor for Problems
Verifying that deployed features didn’t break on their way into production is an essential pre-release quality check. However, teams also need to ensure they can measure a feature’s performance and value over its life-span. The insights that drive this critical feedback loop come primarily from robust monitoring capabilities, which must be in place before release.
Effective monitoring requires that full-stack telemetry is active for all features deployed through the Continuous Delivery Pipeline. This ensures that system performance, end-user behavior, incidents, and business value can be determined rapidly and accurately in production. That information allows tracking and monitoring of each feature, which increases the fidelity of the assertions about business value delivered, as well as increased responsiveness to production issues.
While some business-value metrics cannot be collected until release, teams need to make sure they know how to measure them once the decision to release occurs. Three practices help support this:
- Full-stack telemetry – the ability to monitor for problems across the full stack that a system covers
- Visual displays – tools that display automated measurements
- Federated monitoring – consolidated monitoring across applications in the solution that creates a holistic view of problems and performance
Respond and Recover
The ability to respond to and recover from unforeseen production issues is critical to supporting continuous deployment and streamlining the Continuous Delivery Pipeline. The reasons are obvious:
- Production issues affect customers and end users directly, so the value of deployed solutions can erode quickly when problems occur
- Production issues spawn rework—fixes, patches, redevelopment, retesting, redeployment, etc. That disrupts the normal flow of value through the pipeline
Because production issues can harm delivery efficiency and lower value, teams must ensure that they can detect issues proactively and recover quickly. In fact, fast recovery, as measured by Mean Time to Restore (MTTR), is among the most reliable leading indicators of high DevOps maturity. [5] Recovery is also one of the five elements of SAFe’s CALMR approach to DevOps.
The goal of respond and recover is to identify potential issues before they turn into incidents and to prevent them from affecting business operations. This requires the ability to detect difficulties internally before end users discover them, quickly identify root causes, and restore services with well-rehearsed procedures. In contrast, making hasty, reactive changes directly to production systems—‘just to keep the lights on’—invites configuration drift, unverified changes, and long-term risk.
Six practices support the ability to respond and recover from production issues:
- Proactive detection – a practice for proactively creating faults in the solution to identify potential problems and situations before they occur
- Cross-team collaboration – a mindset of cooperation across the Value Stream to identify and solve problems as they arise
- Session replay – the ability to replay end-user sessions to research incidents and identify problems
- Rollback and fix forward – the ability to both rollback a solution quickly to a previous environment, or to fix a problem quickly through the pipeline without the need to rollback
- Immutable infrastructure – this concept recommends that teams never change the elements of the production environment in an uncontrolled manner, but instead manage infrastructure changes through the Continuous Delivery Pipeline
- Version control – environments should be maintained under version control in order to rollback quickly
After teams have demonstrated that features have been deployed successfully to production, and that the necessary monitoring and recovery capabilities are in place to track and manage ongoing value, they have completed the continuous deployment stage of the Continuous Delivery Pipeline. In turn, this gives the enterprise the ability to release whenever warranted.
Enabling Continuous Deployment with DevOps
Continuous deployment involves important ‘operations’ activities that are frequently associated with the ‘Ops’ in DevOps. These activities are focused on deploying solutions to production environments, verifying their functional integrity, and ensuring they can be effectively monitored and supported post-release.
As Figure 3 illustrates, continuous deployment is enabled by SAFe’s CALMR approach to DevOps (center) as well as several practice domains (inner rings). Each of the four activities (in green) is a collaborative effort that draws upon DevOps expertise from multiple domains to maximize delivery speed and quality.
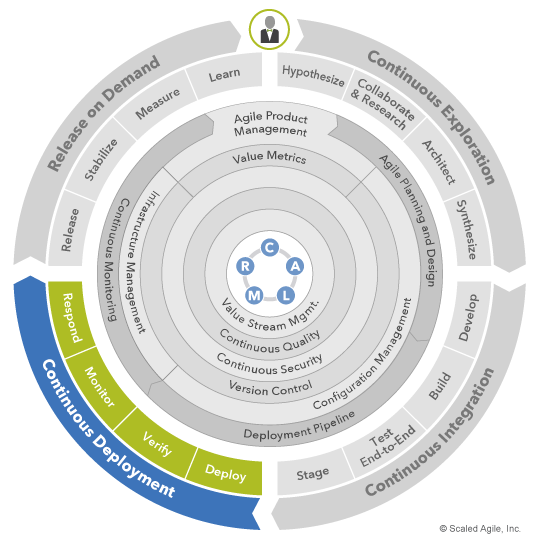
For instance, deploying solutions in the continuous delivery pipeline involves invoking tools that automate the provisioning of production infrastructure, deploy solution binaries to select targets, verify production functionality, capture runtime telemetry, and proactively alert on issues. DevOps practices and tools streamline these capabilities, allowing solutions to be deployed and fully prepared for on-demand release in a matter of minutes.
All four continuous deployment activities are enabled by DevOps, though with different combinations of technical practices and tooling. For more guidance on DevOps and how it enables the continuous delivery pipeline, see the DevOps article series.
Learn More
[1] Kim, Gene, et al. The Phoenix Project: A Novel About IT, DevOps, and Helping Your Business Win. IT Revolution Press, 2013. [2] Kim, Gene, Jez Humble, Patrick Debois, and John Willis. The DevOps Handbook: How to Create World-Class Agility, Reliability, and Security in Technology Organizations. IT Revolution Press, 2016. [3] Humble, Jez, and David Farley. Continuous Delivery: Reliable Software Releases through Build, Test, and Deployment Automation. Addison-Wesley, 2010. [4] Gregory, Janet, and Lisa Crispin. More Agile Testing: Learning Journeys for the Whole Team. Addison-Wesley Signature Series (Cohn). Pearson Education, 2014. [5] 2017 State of DevOps Report. https://puppet.com/resources/whitepaper/state-of-devops-report
Last update: 27 September 2021